The robots.txt file is a simple text file located on your website’s server that guides web crawlers or bots on how to navigate and crawl your site’s pages.
As part of the Robots Exclusion Protocol (REP), it primarily serves to manage crawler traffic and prevent specific pages or sections of your site from being indexed by search engines.
In this article:
Importance of robots.txt
- Control Over Web Crawlers: It tells web crawlers which pages they can and can’t visit, helping you manage how search engines see your site.
- Protect Sensitive Information: It can block crawlers from accessing pages with private or sensitive information.
- Optimize Crawl Budget: By blocking non-essential pages, it ensures that search engines focus on the most important parts of your site.
- Improve Site Performance: Reducing the number of pages crawled can lower server load and improve overall site performance.
- Prevent Duplicate Content: It helps prevent search engines from indexing duplicate content, which can improve your site’s search rankings.
- Maintain Site Security: It can be used to block access to administrative and secure areas of your site.
- Enhance User Experience: By managing crawler access, it ensures that users find the most relevant and important content when they search for your site.
Check your website’s robots.txt
In order to open the robots.txt file of your website, follow the steps mentioned below:
- Open your web browser (like Chrome, Firefox, or Safari).
- In the address bar, type the URL of your website followed by ‘/robots.txt‘ (without quotes).
- For example, if the URL of your website is www.example.com, then you need to type www.example.com/robots.txt to open the file.
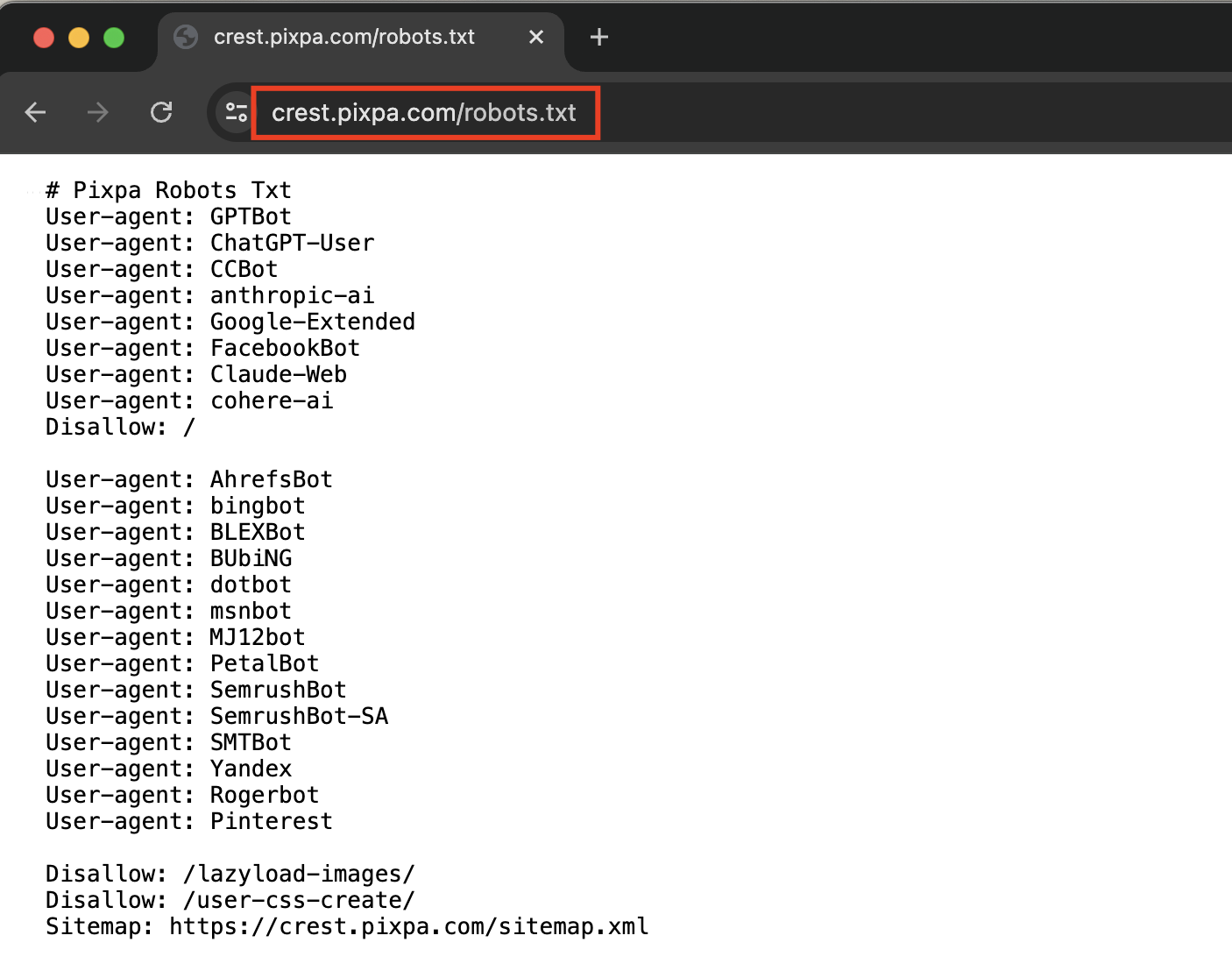
Directives inside robots.txt
- User-agent: Specifies the web crawler to which the rules apply. An asterisk (
*) means the rules apply to all crawlers. - Disallow: Tells crawlers not to access a specific URL path.
- Allow: Overrides a
Disallowdirective to permit access to a specific URL path. - Sitemap: Specifies the location of the sitemap file, which helps search engines understand the structure of your site.